Introduction:
Azure Kubernetes Service (AKS) empowers you to dynamically scale your applications to meet fluctuating demands. By leveraging CPU and memory-based autoscaling, you can optimize resource allocation, minimize costs, and ensure your applications consistently deliver peak performance. This guide will walk you through the process of configuring and implementing effective autoscaling in Azure Kubernetes Service deployment.
By default, the Horizontal Pod Autoscaler (HPA) in Kubernetes primarily uses CPU utilization as a metric for scaling. However, it is also possible to configure HPA to use memory utilization or custom metrics. Here’s how you can set up HPA to consider memory usage in addition to CPU usage.
What is HPA?
Horizontal Pod Auto scaler (HPA) automatically scales the number of pods in a Kubernetes deployment based on observed metrics such as CPU and memory usage. It ensures your application can handle increased load and conserves resources when demand is low.
“AKS Autoscaling automatically adjusts the number of pods in your deployments, ensuring your applications can seamlessly handle fluctuating workloads.”
Why we monitor Memory and CPU Utilization?
In many applications, both memory and CPU usage are critical metrics to monitor. Memory-intensive applications require additional resources to maintain performance, so scaling based on memory ensures pods are added when usage increases, preventing performance degradation due to memory pressure. Similarly, CPU utilization is essential because high CPU demand can quickly lead to processing bottlenecks. By monitoring and autoscaling based on both memory and CPU, you achieve a more holistic and balanced approach that ensures your applications have the necessary resources to operate optimally under varying workloads.
Step-by-Step Guide to Configure AKS autoscaling
Prerequisites
Before we begin, ensure you have the following:
- Azure CLI installed and configured on your machine.
- kubectl installed and configured to interact with your AKS cluster.
- An AKS cluster up and running.
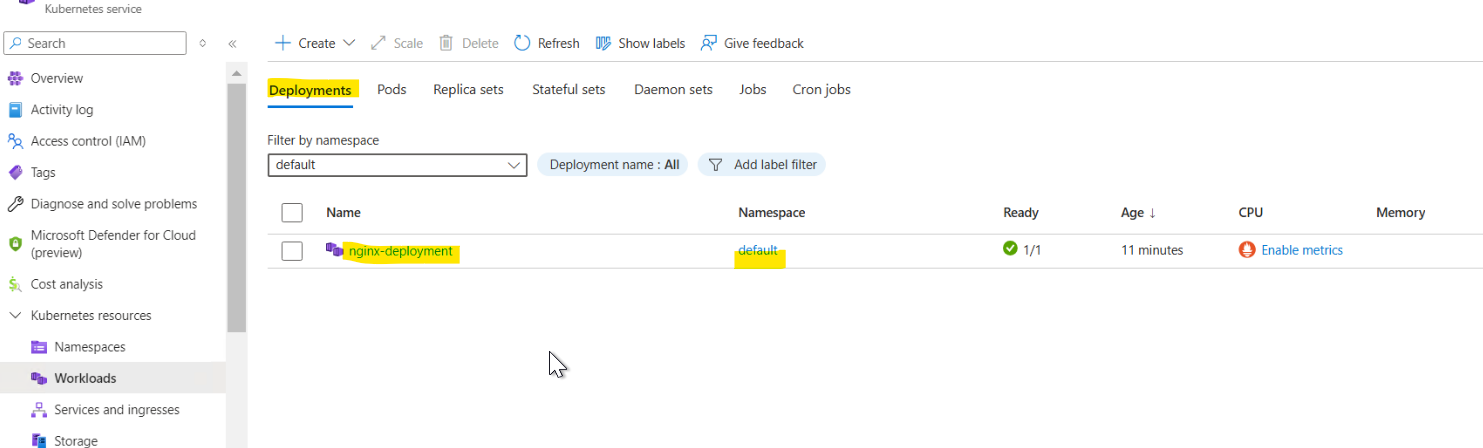
Step 1: Create a Deployment
First, Create a simple deployment using kubectl apply. Let’s create a simple NGINX deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Save this YAML file as nginx-deployment.yaml and apply it using kubectl:
kubectl apply -f nginx-deployment.yaml
This will create a deployment named nginx-deployment with one replica of the NGINX container.
Step 2: Create the HPA with Memory Utilization
To create an HPA that uses both CPU and memory metrics, you need to define the metrics in the HPA configuration (Define an HPA that considers both CPU and memory utilization). Save the following YAML as hpa-nginx.yaml:
To associate the Horizontal Pod Autoscaler (HPA) with the specific deployment created in Step 1 (nginx-deployment), the autoscaling YAML must specify the kind: Deployment and name: nginx-deployment within the scaleTargetRef section, as shown in the example below.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 70
Apply the HPA configuration:
kubectl apply -f hpa-nginx.yaml
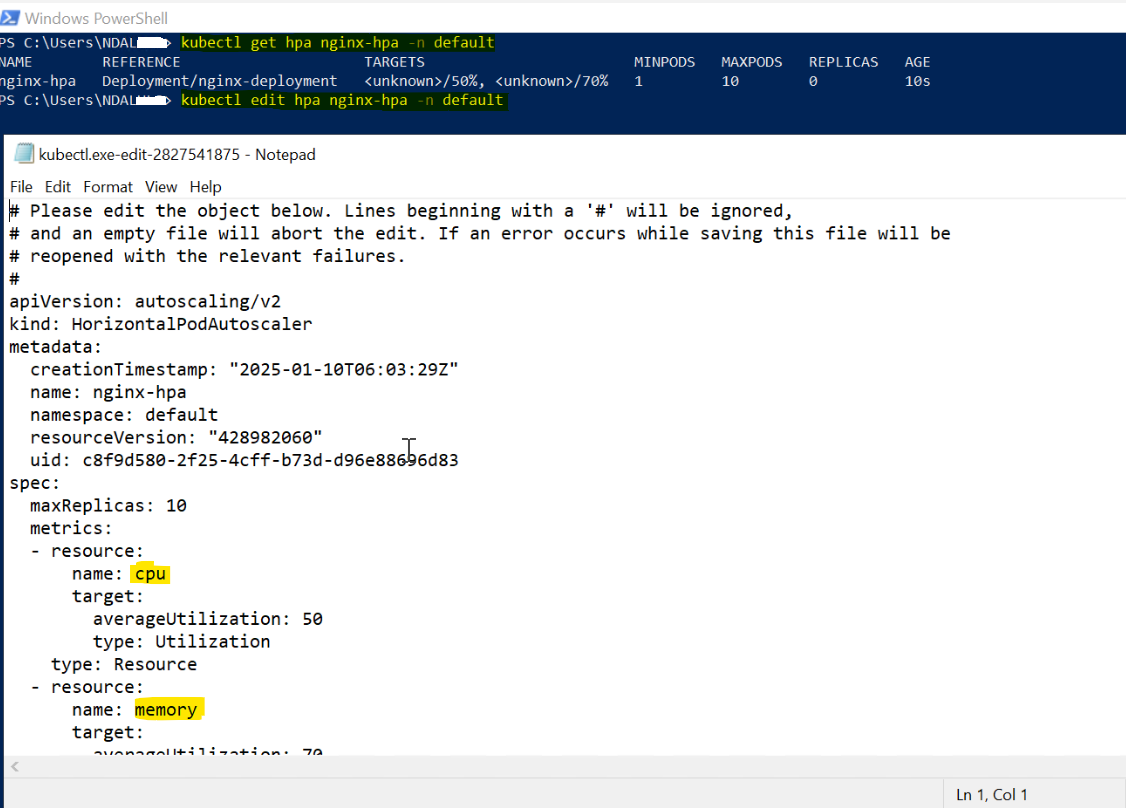
Step 3: Verify the HPA
Check the status of the HPA to ensure it includes both CPU and memory metrics: Use kubectl get hpa to confirm the HPA is configured correctly and includes both CPU and memory targets.
kubectl get hpa nginx-hpa
The output should display both CPU and memory utilization targets:
Step 4: Modify the HPA Configuration:
If you need to adjust the scaling parameters (e.g., minReplicas, maxReplicas, CPU/memory utilization targets), edit the hpa-nginx.yaml file accordingly as shown below and update the new value and save. For example, to increase the maximum number of replicas:
Key Considerations:
- Monitor HPA Behavior: Regularly monitor the HPA’s behavior using kubectl describe hpa nginx-hpa. This will provide insights into the scaling activities, current pod count, and the reasons for scaling up or down.
- Fine-tune Metrics: Experiment with different CPU and memory utilization targets to find the optimal values for your application’s workload.
- Consider Custom Metrics: For more complex scenarios, explore using custom metrics for autoscaling (e.g., request latency, error rates).
Conclusion:
By following these steps, you can effectively update your HPA configuration in AKS to ensure your deployments scale efficiently and effectively based on both CPU and memory utilization. By incorporating memory utilization into your AKS autoscaling strategy, you optimize resource allocation, minimize costs, and enhance application performance. This proactive approach ensures your applications seamlessly handle varying workloads while maintaining high availability and delivering an exceptional user experience. Regularly monitor your HPA metrics and adjust scaling parameters as needed to fine-tune performance and achieve optimal resource utilization.